To appear
Previous: 3 Compression Review
We started by experimenting with several lossless compression techniques on
adir512,
a  reduction of the USGS Lake Champlain West DEM, shown in
Figure f:512.he
reduction of the USGS Lake Champlain West DEM, shown in
Figure f:512.he![]() , obtained from
the
, obtained from
the  DEM with the program pnmscale. This is not
one corner of the DEM, but is the whole DEM at a lower resolution. We used
this conservative choice since a
DEM with the program pnmscale. This is not
one corner of the DEM, but is the whole DEM at a lower resolution. We used
this conservative choice since a  corner of the DEM, with the
points still spaced at
corner of the DEM, with the
points still spaced at  , would have compressed either better or worse
depending on which corner we used, as shown later in Table t:part.
The file contains a mix of a mountainous region in the southwest, with a
plane in the center west and a lake in the center east. The 262,144
points range in elevation from 22 to 1,568 meters.
, would have compressed either better or worse
depending on which corner we used, as shown later in Table t:part.
The file contains a mix of a mountainous region in the southwest, with a
plane in the center west and a lake in the center east. The 262,144
points range in elevation from 22 to 1,568 meters.
The purpose of these experiments was to determine the relative performance
of the various methods, so that we could select a few methods to apply to
files of various sizes. The next test case was adir1024, a
 corner of the Lake Champlain West DEM, first whole, then
partitioned into smaller and smaller blocks. This demonstrated that altho
a particular method might compress different files of the same size by
amounts ranging over a factor of three, the relative performance of
different methods applied to the same file did not vary much. This is why
these experiments might have some general validity on other data sets.
corner of the Lake Champlain West DEM, first whole, then
partitioned into smaller and smaller blocks. This demonstrated that altho
a particular method might compress different files of the same size by
amounts ranging over a factor of three, the relative performance of
different methods applied to the same file did not vary much. This is why
these experiments might have some general validity on other data sets.
Finally we tested a few methods on a  block of 24 other randomly
selected DEMs. We saw the same behavior again. Altho compression ratios
varied over a factor of 10, the ratio of the size achieved by the
progcode method to the size achieved by gzip, varied by
only a factor of 2.
That is,
block of 24 other randomly
selected DEMs. We saw the same behavior again. Altho compression ratios
varied over a factor of 10, the ratio of the size achieved by the
progcode method to the size achieved by gzip, varied by
only a factor of 2.
That is,

In the following numbers, we will generally ignore header information in the files since the headers are a small fraction of the file size, which fraction gets smaller as the data gets larger.
The raw ASCII file, with each point stored as three to five characters, depending on the number of digits in the elevation (plus a separator), as takes 964,532 bytes. Using a binary file with two bytes per number reduces the space to 524,288 bytes. This is a smaller reduction than expected since 33.6% of the elevations are only 2 digits. Nevertheless, the binary file is useful since it is much faster to read since formatted I/O is rather compute-bound.
The Unix compress command, applied to the ASCII file, produces a 289,408 byte file, altho in only 3 CPU seconds on a Sun Sparc 10/30 workstation. A better compression program is gzip, part of the Free Software Foundation suite of free GNU software. gzip has an option for the amount of time spent to compress. At the default setting, applied to the original ASCII file, the compressed file is 263,270 bytes, produced in 21 seconds. gzip -9, the slowest smallest setting, produces a file of 258,016 bytes in 37 seconds. Since the latter took almost twice as long to compute, the default setting is probably appropriate.
Gzip, in 7 seconds, compresses the above binary file to 230,889 bytes. Gzip -9 creates a slightly smaller 230,179 byte file in 14 seconds. This shows that treating the file as numbers, rather than as simple text is somewhat better. How good might we potentially do?
Among the 262,144 points, there are only 1,436 different
elevations. Thus, a table of the existing elevations plus 10 bpp
are almost sufficient. What is the information-theoretic Huffman
lower bound, ignoring relations between adjacent points? Let
 be the number of points with the i-th elevation, counting
from lo to hi, and let the total number of points be
be the number of points with the i-th elevation, counting
from lo to hi, and let the total number of points be 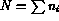 .
Then lower bound, also called the entropy of the data, is, in
bits,
.
Then lower bound, also called the entropy of the data, is, in
bits,

For this data, the frequencies range from 71 elevations occurring once, to one elevation occuring 28,674 times. The entropy is 280,753 bytes, or 8.6 bpp. Clearly, ignoring correlations in the elevations is expensive.
The above entropy calculation ignores autocorrelations in the data.
Therefore consider a 1-D differencing, along a linear array of the points.
There were 501 different differences ranging from --158 to +750, with 156
deltas occurring once,  occurring 80,125 times, and the next most
frequent delta occurring 15,577 times. The resulting file's entropy is
163,125 bytes, or 5.0 bpp, so using deltas gave us a factor of
1.7.
occurring 80,125 times, and the next most
frequent delta occurring 15,577 times. The resulting file's entropy is
163,125 bytes, or 5.0 bpp, so using deltas gave us a factor of
1.7.
To appear
Previous: 3 Compression Review